pgflow 0.7.2 fixes missing realtime broadcasts that prevented clients from receiving step:started and step:completed events. PostgreSQL’s query optimizer was eliminating CTEs containing realtime.send() calls because they weren’t referenced by subsequent operations.
pgflow has transitioned from alpha to public beta. Core functionality is stable and reliable,
with early adopters already running pgflow in production environments.
This milestone reflects months of testing, bug fixes, and real-world usage feedback. The SQL Core,
DSL, and Edge Worker components have proven robust across different workloads and deployment scenarios.
See the project status page for production recommendations and known limitations.
Map steps enable parallel array processing by automatically creating multiple tasks - one for each array element.
import { Flow } from'@pgflow/dsl/supabase';
const BatchProcessor = newFlow<string[]>({
slug: 'batch_processor',
maxAttempts: 3,
})
.map(
{ slug: 'processUrls' },
async(url)=> {
// Each URL gets its own task with independent retry
returnawaitscrapeWebpage(url);
}
);
Why this matters:
When processing 100 URLs, if URL #47 fails, only that specific task retries - the other 99 continue
processing. With a regular step, one failure would retry all 100 URLs.
This independent retry isolation makes flows more efficient and resilient. Each task has its own
retry counter, timeout, and execution context.
Map steps handle edge cases automatically:
Empty arrays complete immediately without creating tasks
Type violations fail gracefully with stored output for debugging
Results maintain array order regardless of completion sequence
Array steps are a semantic wrapper that makes intent clear and moves type errors from .map() to .array(). When a map step depends on a regular step that doesn’t return an array, the compiler catches it too - .array() just makes the error location more precise and the code intention explicit.
The @pgflow/client package, initially released in v0.4.0 but never widely announced, now has complete documentation. This type-safe client powers the pgflow demo and provides both promise-based and event-based APIs for starting workflows and monitoring real-time progress from TypeScript environments (browsers, Node.js, Deno, React Native).
Features include type-safe flow management with automatic inference from flow definitions, real-time progress monitoring via Supabase broadcasts, and extensive test coverage.
The entire documentation has been reorganized from a feature-based structure to a
user-journey-based structure, making it easier to find what you need at each stage of using pgflow.
Before
After
New documentation includes:
Build section - Guides for starting flows, organizing code, processing arrays, and managing versions
Deploy section - Production deployment guides for Supabase
Concepts - Understanding map steps, context object, data model, and architecture
The homepage has been completely rebuilt with animated DAG visualization, interactive before/after code comparisons, and streamlined messaging. Visit pgflow.dev to explore the new experience.
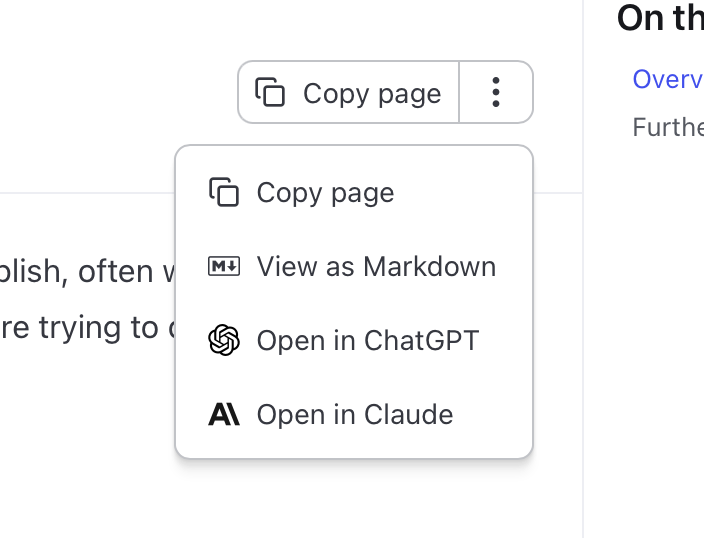
Copy to Markdown on All Docs Pages - Every documentation page now includes contextual menu buttons to copy the page as markdown or open it directly in Claude Code or ChatGPT for context-aware assistance.
Additional improvements:
Full deno.json Support - pgflow compile now uses --config flag for complete deno.json support
Fixed config.toml Corruption - CLI no longer corrupts minimal config.toml files (thanks to @DecimalTurn)
Better Type Inference - Improved DSL type inference for .array() and .map() methods